Quase 10 anos depois vamos começar a usar o GIT. Acompanhe nossa história e veja um pequeno manual para você aproveitar o que já sabe sobre o TFVC para aprender a usar o GIT no Visual Studio. Neste artigos abordo apenas sobre versionamento de arquivos, as ferramentas colaborativas, checkin police, issue tracker e etc terão sua vez assim que formos nos adaptando com o Github.
Nossa pequena história
Lembro como se fosse ontem a animação ao configurar o cliente do TFVC, naquela época estávamos migrando do então famigerado Microsoft SourceSafe, para esse que então era promessade dias melhores no ambiente de trabalho.
O Team Foundation Version Control era lindo, vinha com a promessa de ser a ferramenta ideal para o versionamento de arquivos para projetos maiores, robusto e totalmente configurável com seu maravilhoso diff e merging que realmente funcionavam fizeram sucesso (e ainda fazem) dentro da nossa equipe.
Dávamos a deus as anotações \\DONEBY: e as horas perdidas com mergins praticamente manuais. Os ventos da mudança assobiavam no nosso escritório.
Quase 10 anos depois, novamente movidos pela necessidade, estamos migrando, desta vez do, amado e companheiro TFVC, para o GIT. Mas por quê? Parece bobo, mas a principal razão é de ele não ser rápido o suficiente.
Embora não exista um limite para a quantidade de itens que você possa ter em um mesmo workspace, quando este número cresce, a performance do Visual Studio reduz drasticamente, isso é indiscutível. Claro, existem formas de reduzir este efeito, mas o fato é que há um momento que não adianta mais, e assim somos obrigados a buscar novas opções.
Agora o GIT, que além de ser um excelente controlador de versões, robusto, mantido por uma comunidade enorme, tem como principal promessa ser extremamente rápido.
E como tem sido! Nossos testes iniciais mostraram que usá-lo com o Visual Studio tornará nosso trabalho incontáveis minutos mais rápidos. Exemplo claro fica quando decidimos mudar de uma branch para outra, processo que no TFS levava em média até um minuto completo, com o GIT acontece quase que instantaneamente1.
Provando ser uma escolha natural para quem se acostumou com um produto que é fácil de usar e funciona.
Passos iniciais com o GIT para um Desenvolvedor TFVC
Git é muito mais simples do que o TFVC e a primeira coisa que você perceberá ao a usá-lo será sua terminologia, alguns conceitos um pouco diferentes e falta e/ou inclusão de recursos, que acabam fazendo com que tudo pareça confuso, mas fique tranquilo, abaixo listo as principais diferenças entre os dois.
Adeus workspaces
Um recurso obrigatório e muito importante no TFVC não existe no GIT. Para você começar a trabalhar com o GIT não é preciso que você crie workspaces, configurando diretórios, local de arquivos, permissões e etc. Apenas escolha um diretório no seu computador clone o repositório que você deseja trabalhar e mãos a obra.
Branch são mais simples
Ele realmente brilha nesse quesito, ao contrário do TFVC que te obriga a copiar todos os arquivos do projeto atual em um diretório diferente para uma nova branch, O GIT é esperto o suficiente para gerenciar sozinho as diferenças entre os arquivos entre as branchs usando mesmo diretório.
Nada de Check in ou Check out’s
Git não possui conceito de lock de arquivos, você pode editar e ‘submeter’ qualquer arquivo a qualquer momento para o repositório central em qualquer branch2, mas atenção checkout no GIT tem outro significado.
Isso tem um efeito interessante, para evitar dores de cabeças futuras desde o início as equipes se veem na obrigação de concordarem entre sim e trabalharem seguindo determinado padrão para garantir que não hajam problemas de conflitos.
Dentre eles o mais conhecido e utilizado é o git-flow que basicamente usa branchs para organizar as atualizações sobre a base de código.
Repositórios locais e no servidor
Assim como o TFVC possui repositórios locais e no servidor o GIT também, mas conceitualmente diferentes.
No TFVC quando você usa a opção de repositório local, a cada operação (checkin, checkout, shelve etc) o TFVC verifica o conteúdo de cada arquivo no workspace com os arquivos que estão no repositório do servidor, já para repositórios no servidor a verificação é apenas no byte informativo de readonly.
Já no GIT é diferente, você sempre trabalhará no seu repositório local enviando apenas para o servidor quando o trabalho estiver pronto.
Commits, fetch, pull, push e sync
No TFVC existem basicamente duas formas de você trabalhar com arquivos:
check outque basicamente diz ao TFVC que você deseja editar o arquivo e ocheck inonde você envia as alterações feitas para o repositório central visível a todos.shelveandunshelveanálogo ao anterior, porém as alterações ficam apenas disponíveis para você.
Já no GIT o fluxo de trabalho é diferente, primeiro é preciso que você entenda que o seus arquivos sempre estarão em um de quatro estados diferentes:
untrackedcomo nome já diz, são arquivos que o git não está acompanhando. Arquivos que não estavam presentes no último commit e ainda não foramstaged;unmodifiedarquivos que constavam no último commit e não foram modificados;modifiedarquivos que constavam no último commit e foram modificados mas ainda não foram stageds;stagedarquivos que estão prontos para fazer parte do próximo commit;
Fluxo de estados dos arquivos
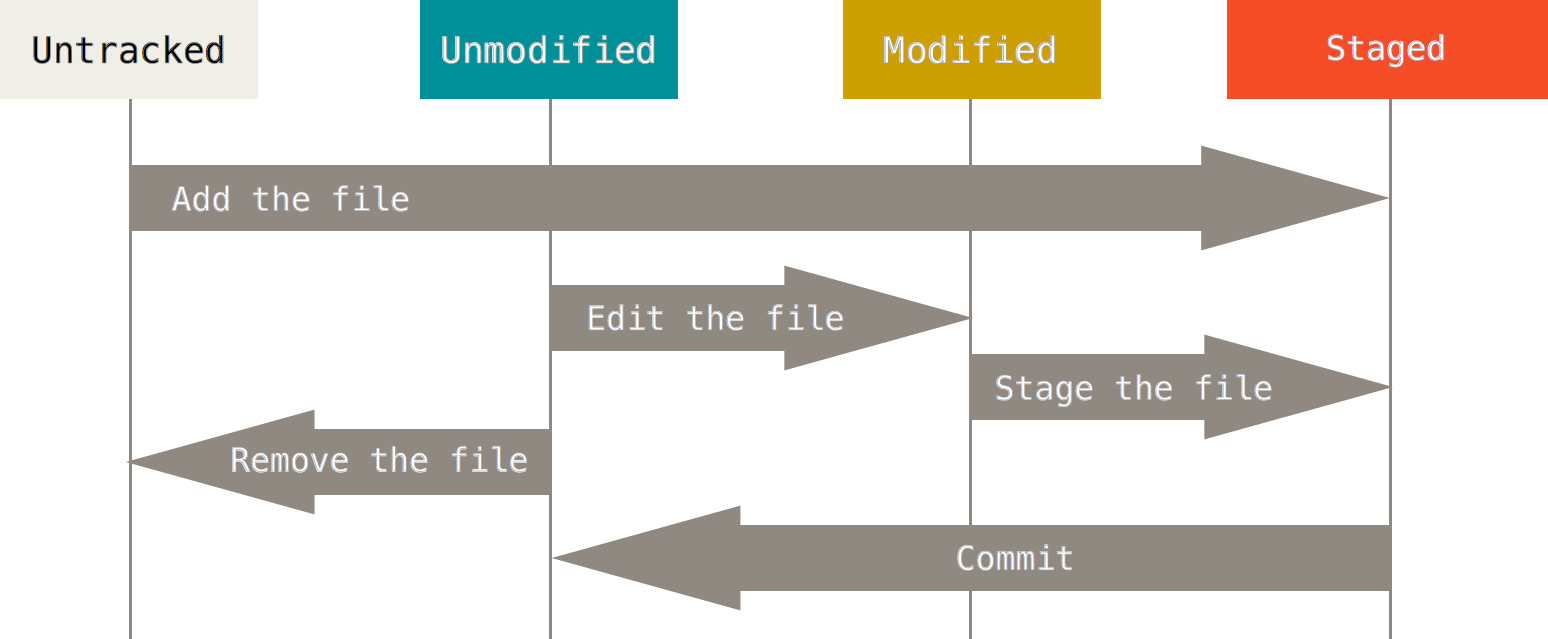 De onde e para onde um arquivo pode ‘pular’ durante seu ciclo, fonte: https://git-scm.com/
De onde e para onde um arquivo pode ‘pular’ durante seu ciclo, fonte: https://git-scm.com/
commit
Uma boa analogia seria compará-los com o recurso de restauração do windows, onde ‘pontos de restauração’ são gravados antes de alterações importantes sejam feitas no sistema, permitindo que, caso as coisas deêm errado, você possa retornar a uma versão segura.
Os commits no GIT são uma ferramenta importante que permitem que os desenvolvedores além de salvarem seu progresso demarcando pontos seguros em que poderão voltar caso algo de errado, eles também quando bem feitos podem servir como uma exelente meio para automatização de documetanção.
Não se esqueça que apenas os arquivos stageds são gravados pelo commit.
fetch
Baixa os HEADs com nomes ou tags do repositório no servidor e seus objetos atualizando seu repositório local SEM que haja merge.
Uma super simplificação seria você pensar que os arquivos que estão no seu computador possuem links de referencias com uma versão de commit do servidor. Quando essa versão muda, você precisa atualizar essa referencia antes de poder enviar novas versões. O que o fetch faz é baixar as atualizações que ocorreram desde a última busca e salvar em uma ‘área especial’ que você poderá inspecionar, se quiser, antes de efetuar um merge.
pull
Já o pull além de buscar os arquivos como o fetch também faz o merge automaticamente para você. Veja esse exemplo
Imagine que este é o estado dos seus repositórios:
A---B---C master no servidor
/
D---E---F---G master <- repositório local
^
origin/master último fetch (ou pull)
Após o PULL o git irá atualizar as referencias do commit G com B e C que foram realizados nos servidor gerando um novo a partir do merge chamado H.
A---B---C master no servidor
/ \
D---E---F---G---H <- repositório local
push
Quando você tiver concluído seu trabalho, corrigido aquele bug ou funcionalidade. Use este comando para enviar suas alterações para o repositório no servidor. Este comando irá pegar todas as alterações que foram commited localmente e os enviará para o servidor. Mas atenção, você só poderá ‘enviar’ se as referencias locais/remoto estiverem atualizadas, então uma boa idéia sempre conferir através do fetch.
sync
Pense no sync como tudo que foi dito acima, mas feito a partir de uma operação de usuário. Ele fará o que for necessário para que o seu repositório local se torne igual ao remoto. Buscando atualizações(fetch), fazendo o merging(merge) e enviando suas alterações(push), deixando algum trabalho a ser feito por você apenas se houver algum conflito.
Conclusão
Sem dúvida o GIT é uma exelente ferramenta que tornou nosso ciclo de desenvolvimento muito mais produtivo. Cada dia que passa e aprendemos mais, mais fácil fica seu uso diário. Realmente foi uma exelente decisão que durará por mais alguns anos.